Every run, on a dashboard
Pass-rate trends, load pulse, and flaky spotlight — per target.
app.glubean.com — Targets / Default · Overview
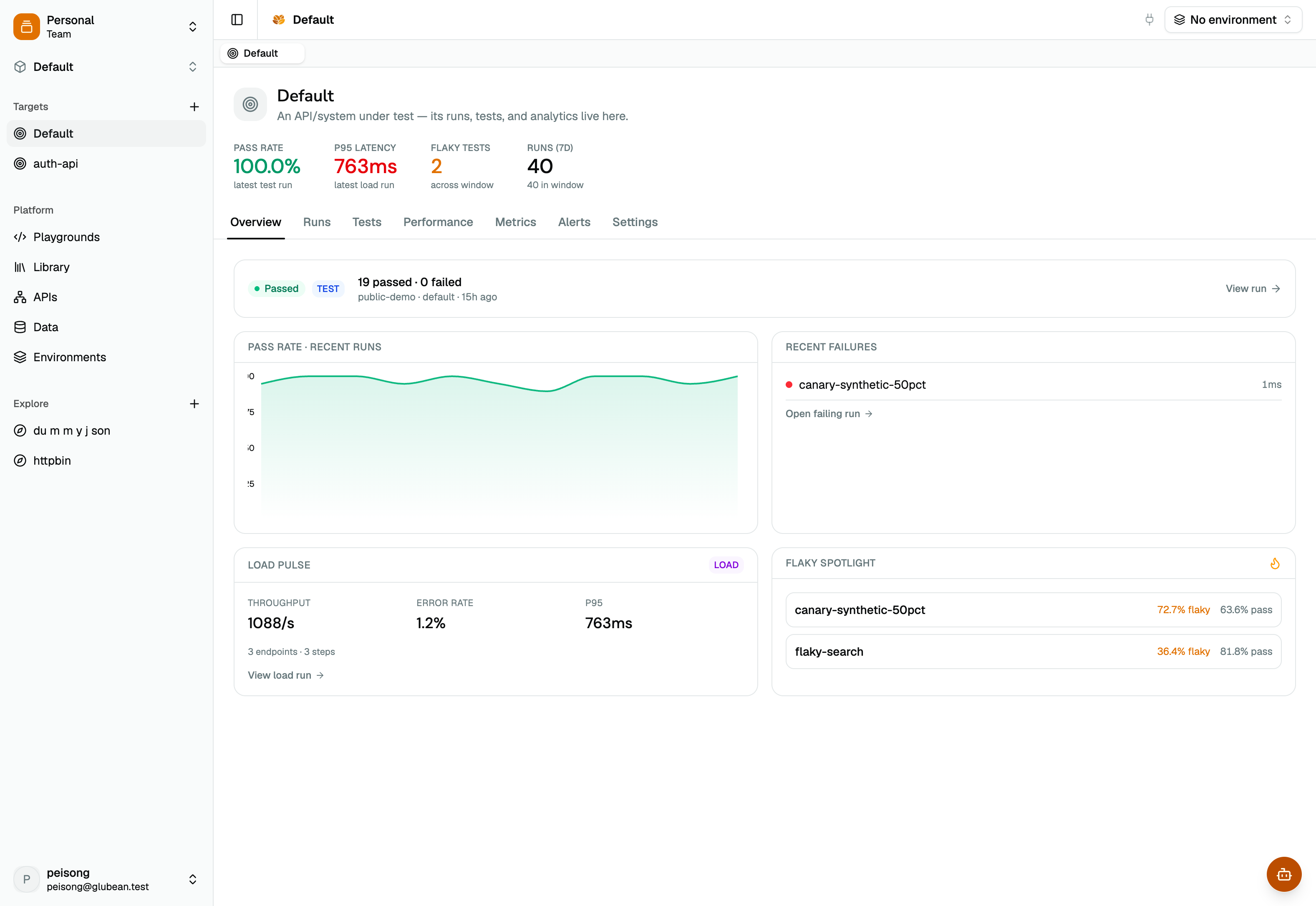
Performance · SLA gates · capacity → p95
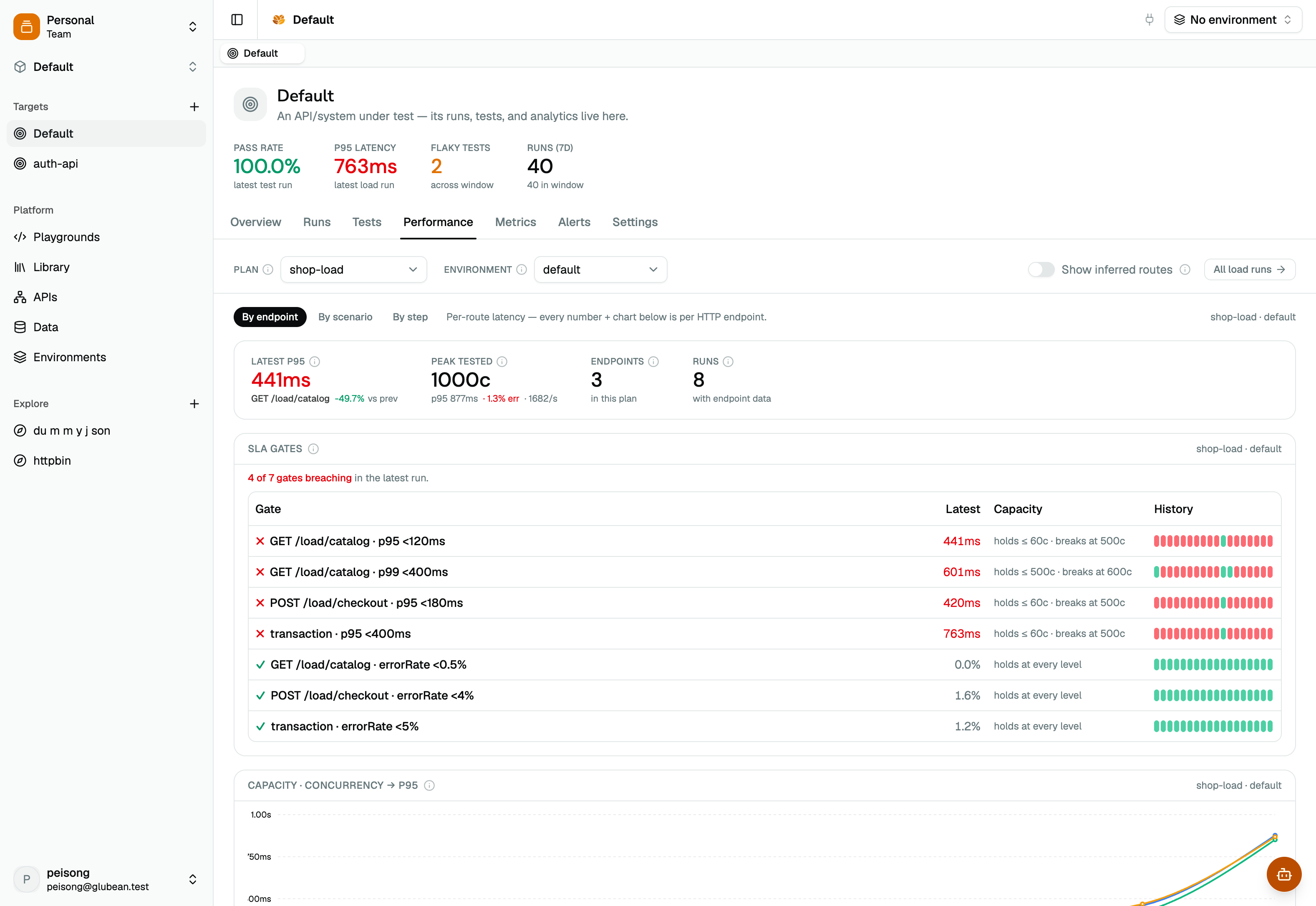
Runs · test + load history
An agent that reads the dashboard
Ask about the run on screen. It answers about that run.
The agent reads structured evidence — not raw logs — then diffs runs, explains regressions, and edits environments, data, specs, and flows. Every write shows a diff before it lands.
Agent · docked beside the dashboard
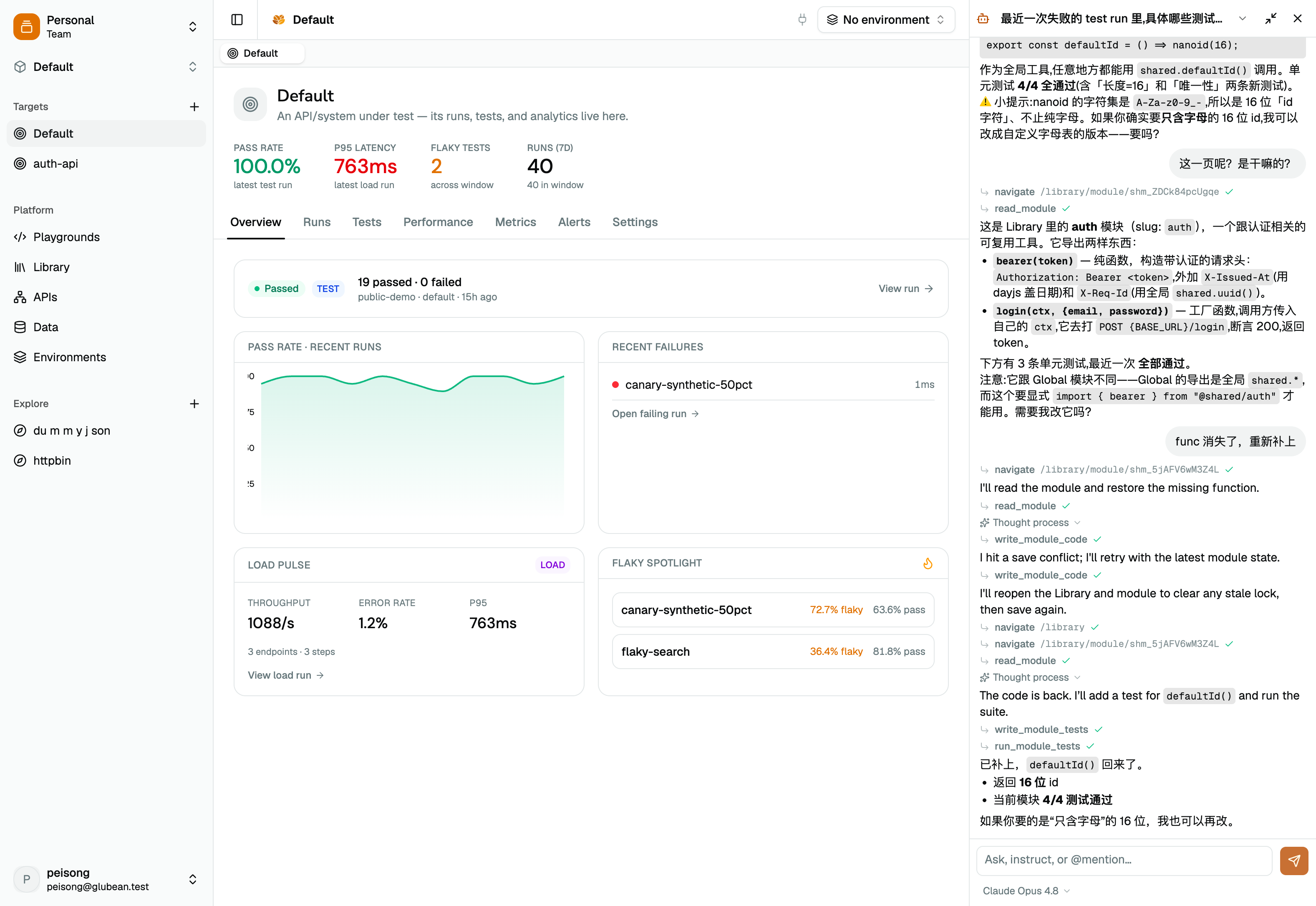
- Diffs two load runs and explains the latency shift
- Answers “did error rate get worse?” from real runs
- Edits env, data, API specs, and flow steps — with a diff
- Never sees your secrets
Evidence, not logs
A failure object says where, why, and what changed.
Cloud keeps the request, response, assertion, and trace as structure — readable enough for people, structured enough for an agent to repair against without quietly weakening the test.
endpointfailed steprequest / responseexpected / actualtrace
failure object
{
"status": "failed",
"testId": "auth.get-me",
"step": "GET /users/me",
"reason": { "kind": "assertion",
"expected": 200, "actual": 401 },
"events": [
{ "type": "http.request", "url": "/users/me" },
{ "type": "http.response", "status": 401 },
{ "type": "assert.failed",
"path": "status", "expected": 200, "actual": 401 }
]
}One evidence layer, many readers
The whole team reads the same run — no code required.
Developersdiagnose failures from structured evidence, not CI logs.
Agentsread the dashboard and suggest what to repair next.
QAreview failures without reproducing locally.
Productcheck API behavior without reading tests.
Supportshare run evidence instead of screenshots.
Trust note
Secrets stay local. Evidence goes to Cloud.
Environment values and token secrets never enter the agent context.
22 redaction rules run before any run reaches the cloud.
glubean redact previews exactly what Cloud receives.